这篇文章不是“安装教程”,而是一份完整工程复盘。
我会把问题、误判、修复路径、回滚策略和运营边界全部写清楚。
目标是让读者不仅能复现,还能在真实环境里稳定运营。
1. 写在前面:为什么要做这次部署
我最初要解决的问题并不复杂:让 OpenClaw 在树莓派上跑起来,并接入 Telegram 日常使用。 但当部署进入第二阶段,很快发现“跑起来”只是最低门槛。
真实场景里还有四个更难的问题:
- 系统一旦重启,服务会不会自恢复;
- 外部网络波动时,机器人是不是立刻“假在线”;
- 暴露到公网后,控制面是否满足安全上下文和最小暴露原则;
- 后续扩展 skills 时,如何控制供应链风险,不让系统慢慢偏离初始可信状态。
所以这次部署从一开始就不是“功能导向”,而是“生命周期导向”:
- 可用性:能启动、能收发、能管理;
- 稳定性:断线可恢复、重启可恢复、升级可恢复;
- 安全性:最小暴露、可审计、可追溯;
- 可运维性:问题可观测、根因可定位、修复可复盘。
这四点缺任何一点,系统都会在后期把复杂度还回来,而且通常是“带着利息还”。
2. 环境与边界:先定义问题,再部署系统
2.1 角色分工
部署中涉及三台主机,职责是明确切开的:
- 树莓派(内网):OpenClaw Gateway 主服务节点;
- NAS(内网):V2rayA 代理节点,负责统一出站;
- 云服务器(公网):FRPS 入口,负责远程访问链路。
这个职责划分非常重要。很多家庭实验环境把“服务、代理、入口”全堆在一台机器上,短期方便,长期不可维护。
2.2 脱敏约定
为避免文章本身变成攻击入口,以下信息全部替换:
- 密码、Token、OAuth code/state、配对码:统一
REDACTED; - 内网地址:统一写成
192.168.31.x或NAS_IP、PI_IP; - 公网地址:统一写成
PUBLIC_SERVER_IP; - 用户名和目录里的个人信息:统一
USER。
2.3 成功标准
这次部署的“完成”,不是主观感觉,而是可验证条件:
openclaw-gateway.service持续active;openclaw gateway probe返回可达;- Telegram 通道
Enabled=ON, State=OK; - 安全审计
critical=0, warn=0; - 技能来源可追溯(commit + sha256);
- 定时巡检启用并落地日志。
3. 架构设计:为什么是“树莓派 + NAS 代理 + FRP”
3.1 最终拓扑
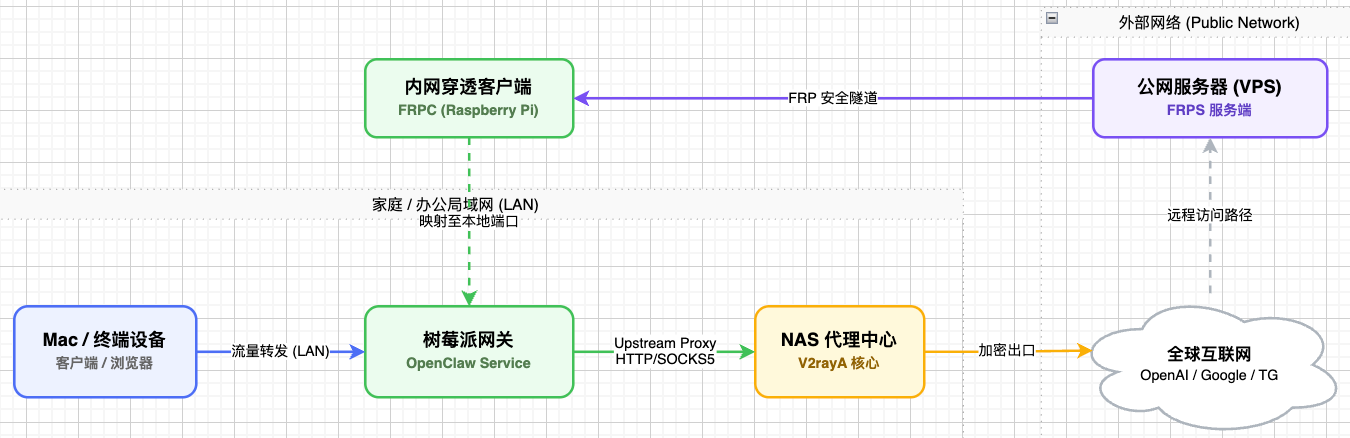
逻辑路径如下:
- 用户本地(Mac)管理 OpenClaw(内网或隧道方式);
- 树莓派运行 OpenClaw Gateway;
- Gateway 的外部请求通过 NAS 的 V2rayA 出站;
- 若需外网访问,通过 FRP 将公网入口映射到树莓派本地端口。
3.2 核心设计取舍
取舍 1:代理不上树莓派本机,而上 NAS
优点:代理集中管理、策略统一、便于切换节点;
代价:增加一跳网络,链路诊断更复杂。
取舍 2:Gateway 默认 loopback 绑定
优点:安全默认值高,避免无意暴露管理面;
代价:外网访问必须通过隧道/反代,配置多一步。
取舍 3:FRP 只做传输,不直接解决浏览器安全上下文
优点:边界清晰,职责单一;
代价:仍需 HTTPS 反向代理才能解决控制台 secure context 约束。
我更倾向这种“多一步但可解释”的方案,而不是“看起来少一步但隐患不可见”的方案。
4. 实施过程全记录(按时间线)
4.1 阶段 A:系统基线与补丁
先完成系统更新,排除老版本依赖引发的非业务问题:
sudo apt update
sudo apt full-upgrade -y
sudo apt autoremove --purge -y
sudo reboot
重启后确认事实状态:
hostname
uname -a
arch
date
这一步的价值在于“建立初始快照”,后续出现异常时可以排除“系统状态未知”。
4.2 阶段 B:OpenClaw 服务化部署
核心原则:永远不要把长期服务交给临时 shell 会话。
操作命令:
systemctl --user daemon-reload
systemctl --user enable --now openclaw-gateway.service
systemctl --user status openclaw-gateway.service
示例服务定义(脱敏):
[Unit]
Description=OpenClaw Gateway
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/usr/bin/node /home/USER/openclaw/package/dist/index.js gateway --port 18789
Restart=always
RestartSec=5
Environment=OPENCLAW_GATEWAY_PORT=18789
Environment=OPENCLAW_GATEWAY_TOKEN=REDACTED
[Install]
WantedBy=default.target
基础验证:
openclaw gateway probe
预期:本地 loopback 可连、RPC 可用。
4.3 阶段 C:Codex 绑定与控制台认证
这里出现了经典错误:
disconnected (1008): unauthorized: gateway token missing
判断逻辑:
- 如果是网络断开,通常是超时或连接失败;
1008 unauthorized明确指向鉴权层。
修复顺序:
- 核对 Gateway token 的来源一致性(服务环境 / 配置文件 / 控制台设置);
- 确认控制台确实提交 token;
- 观察重连日志确认 WS 握手成功。
这一步最容易“误把认证问题当网络问题”,导致浪费大量排障时间。
4.4 阶段 D:接入 NAS 代理并持久化
这一步是整个可用性的关键。
很多人会直接在 shell 里 export HTTP_PROXY=...,然后测试成功,认为完成。
这在服务重启后会全部失效。
正确做法是写入 systemd drop-in:
~/.config/systemd/user/openclaw-gateway.service.d/10-proxy.conf
[Service]
Environment=HTTP_PROXY=http://NAS_IP:HTTP_PROXY_PORT
Environment=HTTPS_PROXY=http://NAS_IP:HTTP_PROXY_PORT
Environment=ALL_PROXY=socks5://NAS_IP:SOCKS5_PORT
Environment=NO_PROXY=localhost,127.0.0.1,::1
生效:
systemctl --user daemon-reload
systemctl --user restart openclaw-gateway.service
验证:
systemctl --user cat openclaw-gateway.service
openclaw status
验证重点是“进程环境”而不是“文件内容”。
4.5 阶段 E:Telegram 通道接入
接入目标不是“Bot 在线”而是“可控在线”。
推荐配置(脱敏):
{
"session": {
"dmScope": "per-channel-peer"
},
"channels": {
"telegram": {
"enabled": true,
"dmPolicy": "pairing",
"botToken": "REDACTED",
"allowFrom": ["TELEGRAM_USER_ID"],
"groupPolicy": "allowlist",
"timeoutSeconds": 30,
"retry": { "attempts": 2 },
"network": { "autoSelectFamily": false },
"proxy": "http://NAS_IP:HTTP_PROXY_PORT"
}
}
}
配对流程:
- 用户
/start触发 pairing; - Bot 返回 pairing code;
- owner 在 OpenClaw 侧 approve;
- 再做主动发送回环测试。
回归命令:
openclaw status
openclaw message send --channel telegram --target TELEGRAM_USER_ID --message "health check"
4.6 阶段 F:FRP 外网访问与控制台安全上下文
当我用公网 HTTP 访问控制台时,报错:
control ui requires device identity (use HTTPS or localhost secure context)
这不是 bug,而是浏览器安全策略。
结论非常清晰:
http://PUBLIC_SERVER_IP:PORT不满足 secure context;- 要么走
localhost(SSH 隧道); - 要么走
https://(反向代理 + 证书)。
FRP 只负责端口映射,不负责浏览器安全上下文。
FRP 示例(脱敏):
frpc.toml
serverAddr = "PUBLIC_SERVER_IP"
serverPort = 7000
auth.method = "token"
auth.token = "REDACTED"
[[proxies]]
name = "rpi-openclaw"
type = "tcp"
localIP = "127.0.0.1"
localPort = 18789
remotePort = 35879
frps.toml
bindPort = 7000
auth.method = "token"
auth.token = "REDACTED"
我最后采用的是:
- 日常管理优先 SSH 隧道;
- 外网长期访问通过 HTTPS 反代接入。
5. 关键故障复盘:真正花时间的不是安装,而是判断
5.1 故障一:Telegram 看似在线但无响应
表象
- Bot 可见;
- 用户发消息后不回、或延迟极高。
常见根因
- 代理链路波动导致 Telegram API 超时;
- pairing 尚未批准;
allowFrom不匹配;- 网关在线但通道线程卡在拉取重试。
标准排查顺序
systemctl --user status openclaw-gateway.service
openclaw status
openclaw logs --follow
openclaw message send --channel telegram --target TELEGRAM_USER_ID --message "loopback test"
这套顺序的核心是:先确认进程,再确认通道,再确认链路,不要反过来。
5.2 故障二:控制台断开 1008
这是最典型的“误判案例”。
- 很多时候第一反应是“代理不稳”;
- 但
1008实际是认证问题,优先核对 token。
排查逻辑一旦反了,通常会花 30 分钟以上在错误方向。
5.3 故障三:公网可打开但不可操作
浏览器报 secure context 时,不要调 OpenClaw。 应当直接切到访问层处理:
- 使用 localhost 隧道;
- 或配置 HTTPS。
这是“平台约束”,不是“应用错误”。
6. 安全加固:把风险从“偶发问题”降到“可控变量”
6.1 告警项一:未信任反向代理头
如果网关前面存在反向代理或转发器,必须显式定义可信代理源。
修复示例:
{
"gateway": {
"trustedProxies": ["127.0.0.1", "::1", "PUBLIC_SERVER_IP"]
}
}
6.2 告警项二:denyCommands 未生效
原因是命令名不精确。 必须与实际命名空间一一匹配:
{
"gateway": {
"nodes": {
"denyCommands": [
"canvas.present",
"canvas.hide",
"canvas.navigate",
"canvas.eval",
"canvas.snapshot",
"canvas.a2ui.push",
"canvas.a2ui.pushJSONL"
]
}
}
}
6.3 审计闭环
修复后必须执行审计:
openclaw security audit --json
验收标准:
critical=0warn=0
不满足就继续修复,不要“带病上线”。
7. 供应链治理:高 Star 只是起点,不是终点
你最初提出“要选 Star 多的项目,担心供应链风险”,这个判断非常专业。
但工程实践里,Star 只能解决“发现效率”,不能解决“可信交付”。
7.1 我采用的四层防线
- 来源防线:优先官方或高信誉组织;
- 版本防线:固定 commit,不追主干漂移;
- 内容防线:安装前静态扫描;
- 运行防线:安装后哈希登记 + 定时校验。
7.2 白名单技能策略
实际策略是“少而精”,不是“多而全”。
- 仅安装当前业务所需 skills;
- 非必要 skill 不进入默认加载路径;
- bundled skills 只保留最小集合,其余 blocked。
7.3 追溯文件
~/.openclaw/skills/.trusted-source-manifest.json
示例:
{
"policy": "high-star-source-only + pinned-commit + manual-scan",
"source_repo": "https://github.com/openclaw/skills",
"source_commit": "REDACTED_COMMIT",
"installed_skills": [
{ "name": "executing-plans", "sha256": "..." },
{ "name": "receiving-code-review", "sha256": "..." },
{ "name": "debug-pro", "sha256": "..." },
{ "name": "test-runner", "sha256": "..." },
{ "name": "skill-vetting", "sha256": "..." }
]
}
这份文件不是“文档”,而是回滚和审计的基线。
8. 可运维化:把“依赖人工”改造成“系统自检”
部署最容易忽略的一点是:
- 修复一次很容易;
- 持续保持正确很难。
所以我把关键动作转成自动化:
8.1 每日完整性巡检
巡检做两件事:
- 检查 skill 文件哈希是否漂移;
- 执行
openclaw security audit --json并记录摘要。
脚本示例路径:
/home/USER/bin/openclaw-integrity-check.sh
8.2 systemd timer 固化
服务和定时器:
~/.config/systemd/user/openclaw-integrity-check.service~/.config/systemd/user/openclaw-integrity-check.timer
启用:
systemctl --user daemon-reload
systemctl --user enable --now openclaw-integrity-check.timer
systemctl --user start openclaw-integrity-check.service
验证:
systemctl --user status openclaw-integrity-check.timer --no-pager
tail -n 50 ~/.openclaw/logs/integrity-check.log
8.3 为什么这个动作值得
因为它把风险检测从“想起来才查”改成“每天自动查”。
后者是系统工程,前者是运气工程。
9. 成本与配额:绑定 Codex 不等于无限额度
这是部署后最常被问的问题之一。
结论很简单:
- 绑定 Codex 解决的是身份和接入;
- 不是自动赠送无限 token。
成本通常由四个变量共同决定:
- 账户套餐与计费规则;
- 模型类型和调用频率;
- 并发与任务编排策略;
- 会话管理方式(上下文长度、历史压缩)。
实操建议:
- 上线当天就打开 usage 观测;
- 对高成本模型设置明确触发条件;
- 为非关键任务配置降级模型;
- 定期清理和压缩历史上下文。
不做这些,账单几乎一定会“后知后觉”。
10. 面向生产的验收清单与日常 SOP
10.1 一次性验收清单
# 1) 服务状态
systemctl --user is-active openclaw-gateway.service
# 2) 网关可达
openclaw gateway probe
# 3) 通道状态
openclaw status
# 4) Telegram 主动发送回环
openclaw message send --channel telegram --target TELEGRAM_USER_ID --message "post-deploy check"
# 5) 安全审计
openclaw security audit --json
# 6) 巡检定时器
systemctl --user status openclaw-integrity-check.timer --no-pager
验收通过条件:
- 六项命令全部成功;
- 安全审计
critical=0, warn=0; - Telegram 收发真实可用。
10.2 每周维护 SOP(建议)
每周一次:
- 检查 gateway 与 timer 状态;
- 抽查最近 7 天巡检日志;
- 验证 Telegram 回环;
- 检查 FRP 映射是否仍符合最小暴露;
- 评估技能清单是否有“新增但未审计”。
每月一次:
- 系统补丁更新(apt);
- OpenClaw 版本评估与升级窗口;
- 供应链基线更新(仅在审计通过后更新 commit 与 manifest);
- 凭据轮换(bot token / gateway token / FRP token)。
10.3 故障应急优先级
当系统异常时,按这个优先级处理:
- 服务存活(systemd);
- 本机可达(gateway probe);
- 代理链路(NAS 出站);
- 通道业务(Telegram);
- 外网访问(FRP + HTTPS)。
优先级倒置是最常见的低效来源。
11. 结语:这次部署最重要的五个经验
如果只能留下五条,我会保留下面这些:
先把服务变成服务,再谈功能体验。 没有服务化,所有功能都只是“当前 shell 的幻觉”。
网络稳定性是 AI 可用性的前置条件。 模型再强,链路不稳,最终体验就是随机失败。
安全配置必须可验证,而不是“我觉得配了”。 只有审计结果和日志证据,才算修复完成。
供应链控制要做成制度,不要做成一次性动作。 高 Star + 固定 commit + 哈希校验 + 自动巡检,缺一不可。
可运维比可演示更重要。 真正上线后,决定成败的不是首日截图,而是第 30 天的稳定性。
这次部署的价值,不在于“把某个工具装好了”,而在于把一套 AI 代理系统纳入了工程化治理框架:可上线、可维护、可审计、可恢复。
12. 附录
12.1 关键文件地图
~/.openclaw/openclaw.json
~/.config/systemd/user/openclaw-gateway.service
~/.config/systemd/user/openclaw-gateway.service.d/10-proxy.conf
~/.openclaw/skills/.trusted-source-manifest.json
~/bin/openclaw-integrity-check.sh
~/.config/systemd/user/openclaw-integrity-check.service
~/.config/systemd/user/openclaw-integrity-check.timer
~/.openclaw/logs/integrity-check.log
12.2 常用命令速查
# 服务管理
systemctl --user status openclaw-gateway.service
systemctl --user restart openclaw-gateway.service
# 网关与日志
openclaw gateway probe
openclaw status
openclaw logs --follow
# 安全审计
openclaw security audit
openclaw security audit --json
# 技能管理
openclaw skills list
openclaw skills check